

정밀의료의 개념은 2015년 오바마 대통령이 정밀의료에 대한 “White house initiative”를 선언함으로서 널리 사용되 며 개념을 정립하기 시작하였다. 오바마 대통령이 정밀의 료를 선언하게 된 배경은 유전체 검사가 일반화 되기 시작 하여 유전체에 기반한 새로운 진단이 가능하게 됨과 동시 에 의료 빅데이터의 교류가 점차 활성화됨으로서 동의 기 반 100만 코호트 구축이 현실화 된 것에 바탕을 두고 있다 <그림 1>.
정밀의료의 시작은 미국 프래밍험 코호트 연구에 바당을 두고 있다. 70년이 넘게 지속되고 있는 프래밍험 코호트 연구 결과는 1,000편이 넘는 중요한 논문들로 발표된 바 있으며 이는 미국 콜레스테롤 교육 프로그램의 학문적인 근거가 되었다.
이를 통하여 약 50년에 걸쳐 프래밍험 지역에서 심혈관 질환에 의한 사망률이 약 75%가 감소하는 엄청난 성과를 거둔 바 있다.
이에 프레밍험 약 5,000명 정도의 코호트를 백만명으로 늘려야 한다는 의견이 있으나 엄청난 예산이 소요될 수 밖 에 없어 미루어져 왔다. 그러나 앞서 이야기한 바와 같이 의 료정보의 통합이 점차 가시화 됨으로서 고식적인 코호트 연 구에서 자발적인 환자들의 참여와 동적 동의에 기반한 의료 정보의 통합으로 저렴한 비용으로 대규모 코호트 구축이 가 능해 졌으며 유전자 검사 역시 적은 비용으로 방대한 정보 를 얻을 수 있게 되었다.
이를 기반으로 구축된 미국의 대형 연구 프랫폼이 바로 “All of Us(AOU)” 프랫폼이다. 이에 발 맞추어 한국에서도 100만명의 자원자를 모집하고 의료정보 통합 고속도로인 “My healthway”를 통한 의료정보 수집과 유전자 및 여러 생체 검체를 확보하는 “국가 바이오 빅데이터 사업”이 이미 9년간 약 1 조원의 예산으로 2024년에 시작하여 진행되고 있다 이러한 노력들은 미래 산업에 가장 중요한 분야인 바 이오 산업의 주도권을 가지기 위한 국가적인 자원 확보 노력으로서 미국, 영국, 일본, 중국, 핀란드 등등 수많은 나라들이 앞다투어 뛰어들고 있다.
당뇨병에서의 정밀의료 구현 역시 유전자 연구와 의료 빅 데이터 기반의 정보 분석에 기반하고 있다. 약 1,200개의 유 전자 변이가 당뇨병과 관련이 있다고 보고되고 있으나 대부 분의 유전자들은 non-coding 부위의 유전자들로서 이러한 유전자 변이가 실제적으로 당뇨병 발생에 어떻게 기여하는 가에 대해서는 앞으로도 많은 연구가 필요한 상황이다. 다 만 당뇨병의 유전 성향이 다유전자의 열성 유전으로 생각되고 있음으로 여러 유전자 변형 전체를 위험도에 따라 다종 유전형의 위험도(polygenic risk score)를 계산하여 발병 위험도를 예측하고 있다.
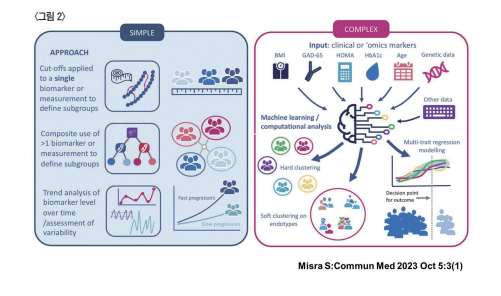
한편으로는 이제까지의 질병 진단과 분류가 <그림 2>에서 보는 것과 같이 몇가지의 생체 지표들의 특성에 의해 규정 해 왔다. 그러나 최근 과학의 눈부신 발전에 기반하여 많은 환자 집단에서 다양한 생체 지표들을 장기간 추적한 빅데이 터에 더하여 방대한 유전체 정보들을 통합하고 이를 다양한 분석 방법을 이용하여 분석함으로서 새로운 질병 분류들이 제시되고 있다.
이러한 새로운 환자 군에 대한 분류는 환자의 모든 특징 을 망라한 다음 인공지능을 이용하여 군집함으로서 얻게 된 새로운 분류 형태로서 이제까지의 단순한 병인을 바탕으로 한 질병 분류 보다는 각 군에 속한 환자들의 임상적 특징, 다 양한 합병증에 대한 상대 위험도, 치료에 대한 반응 예측들 을 보다 더 정밀하게 예측할 수 있다.
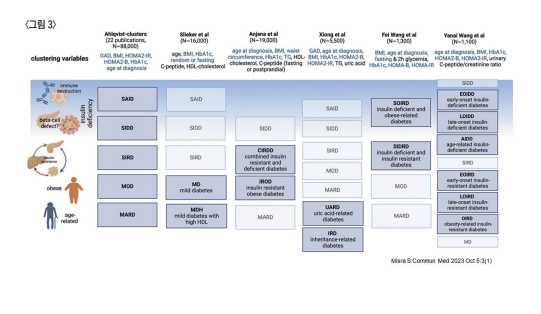
많은 연구들을 통하여 다양한 군집 분류가 제시된 바 있 으며<그림 3> 이러한 분류는 여러 나라의 대규모 코호트를 대상으로 적용해 본 결과 상당히 재현성이 높게 나타남으로 서 그 분류와 유용성에 신뢰를 높이고 있다.
이중 대표적인 스캔디나비아 지역의 연구인 Ahlqvist등이 제시한 클러스터 분류를 보면 1형 당뇨병인 SAID(severe autoimmune diabetes)는 제외하고 2형 분류로는 SIDD(Severe insulin deficient diabetes), SIRD(Severe insulin resistant diabetes), MOD(Mild obesity related diabetes), MARD(Mild age-related diabetes) 등으로 나누 게 되는 데 이 환자 군집들은 각기 잘 반응하는 약제군이 상 이하며 장기적인 추적 조사 결과 호발하는 합병증 역시 상 이한 것으로 보고되고 있다<표 1>.

SIDD의 경우에는 인슐린 분비 기전을 가진 약제들이 추 천되며 망막증, 신경병증 등이 호발하며, SIRD의 경우는 인 슐린 저항성을 개선 시킬 수 있는 약제가 추천되며 호발 합 병증으로는 신증, 심혈관 합병증, 간의 지방 병변 등이 호발 한다. 반면 MARD의 경우에는 심혈관 합병증과 신증이 호 발하는 것으로 알려져 있다.
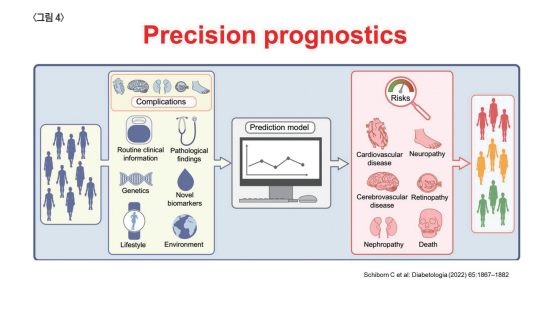
이를 바탕으로 환자는 진단 시작부터 자신에 적합한 치료 약제를 선택할 수 있으며 자신이 쉽게 이환 될 수 있는 합병 증들에 대한 주기적인 진단을 통하여 정밀한 관리를 할 수 있게 된 것이다<그림 4>.
불행히도 우리나라에는 안성-안산, 충주 등의 비교적 대 규모 장기 추적 코호트가 있고, 국가 빅데이터인 심평원 건 강보험공단의 대규모 의료정보가 있음에도 불구하고 당뇨 병에 대한 잘 정제되고 장기 추적 조사된 데이터가 부족하 여 이러한 연구의 진행은 미진한 것이 사실이다.
이러한 연구는 매우 복잡하고 대형 장비가 필요한 연구가 아님으로 일차의료를 바탕으로한 적절한 코호트 혹은 환자 등록이 만들어지고 미리 준비된 프로토콜 하의 진료와 데이 터 수집이 이루어 진다면 얼마든 좋은 자료를 만들어 환자 진료에 응용할 수 있을 것으로 기대한다.
엔도 저널에 관심을 가지시고 성원을 보내주시는 원장님 들과 합심하여 한국형 당뇨병 정밀 예방, 진단, 치료 및 예후 예측 엔진을 만들어 우리 모두 같이 사용할 수 있는 시간이 왔으면 하는 새해 바람을 가져 봅니다.
 제휴문의
제휴문의 공지사항
공지사항 고객센터
고객센터 광고안내
광고안내